[메모리 가상화 #5] 페이징: TLB 본문
개요
- 페이징은 상당한 성능 저하를 가져올 수 있다.
- 페이징은 프로세스 주소 공간을 작은 고정 된 크기 로 나누고 각 페이지의 실제 위치를 메모리에 저장한다.
핵심 질문
- 주소 변환을 어떻게 빨리할 수 있을까?
- 페이징에서 발생하는 추가 메모리 참조를 어떻게 피할 수 있을까?
- 어떤 하드웨어가 추가로 필요할까?
- 운영체제는 어떤식으로 개입하는가?
TLB 의 등장
- 운영체제의 실행 속도를 개선하려면 대부분의 경우 헤드위어로부터 도움을 받는다.
- 변환-색인 버퍼(translation-lookaside buffer) 또는 TLB라고 부르는 것을 도입한다.
- TLB는 MMU의 일부로 자주 참조되는 가상 주소-실주소 변환 정보를 저장하는 하드웨어 캐시이다.
- 가상 메모리 참조 시, 하드웨어는 먼저 TLB에 원하는 변환 정보가 있는지를 확인한다.
- 만약 있다면 페이지 테이블을 통하지 않고 변환을 수행함으로써 페이지 성능을 매우 향상시킬 수 있다.
- 이로써 페이징이 사용가능한 가상 메모리 기법이 된다.
TLB의 기본 알고리즘
1 VPN = (VirtualAddress & VPN_MASK) >> SHIFT // 가상 주소 VPN을 추출한다.
2 (Success , TlbEntry) = TLB_Lookup(VPN) //해당 VPN의 TLB 존재 여부를 검사한다.
3 if (Success == True) // TLB 히트 하면
4 if (CanAccess(TlbEntry.ProtectBits) == True) // 해당 페이지의 접근 권한 검사가 성공하면
5 Offset = VirtualAddress & OFFSETMASK_
6 PhysAddr = (TlbEntry.PFN << SHIFT) | Offset // 그 정보를 원래 가상 주소의 오프셋과 합쳐서 원하는 물리 주소를 구성하고
7 AccessMemory(PhysAddr) // 메모리에 접근한다.
8 else
9 RaiseException(PROTECTION_FAULT)
10 else // TLB 미스 (가상 주소 VPN이 존재하지 않다면)
11 PTEAddr = PTBR + (VPN * sizeof(PTE)) // Base Register를 이용하여 페이지 테이블 주소 계산
12 PTE = AccessMemory(PTEAddr) // 페이지 테이블 접근 (오래 소요되는 작업)
13 if (PTE.Valid == False) // 만약 프로세스가 생성한 가상 메모리 참조가 유효한지
14 RaiseException(SEGMENTATION_FAULT)
15 else if (CanAccess(PTE.ProtectBits) == False) // 프로세스가 생성한 가상 메모리 접근 권한 검사
16 RaiseException(PROTECTION_FAULT)
17 else
18 TLB_Insert(VPN , PTE.PFN , PTE.ProtectBits) // TLB에 저장
19 RetryInstruction() // 명령어 재실행
- 모든 캐시의 설계 철학처럼, TLB도 주소 변환 정보가 대부분의 경우 캐시에있다라는 가정을 전제로 만들어졌다.
- TLB는 프로세싱 코어와 가까운 곳에 위치하고 있고, 매우 빠른 하드웨어로 구성되기 때문에, 주소 변환 작은 그다지 부담스러운 작업이 아니다.
- 미스가 발생하는 경우, 페이징 비용이 커진다. 페이지 테이블을 접근하여 변환 정보를 찾아야 하고 메모리 참조가 추가된다. 이러한 상황이 자주 일어나면 프로그램은 상당히 느려지게 된다.
- 메모리 접근 연산은 다른 CPU연산에 비해 매우 시간이 오래 걸린다. TLB 미스가 많이 발생할수록 메모리 접근 횟수가 많아진다.
예제 : 배열 접근

- 16개의 페이지로 구성된 가상 주소 공간을 표현하고있다
- 가상 주소는 100번지 부터, 10개의 4바이트 크기의 정수 배열이 존재한다.
- 배열에 첫번째 항목은 VPN 06, offset 4에서 시작한다.
- 가상 주소는 4비트 VPN (16개의 VPN을 표시하기 위해) 과 4비트 오프셋(각 페이지는 16바이트 라 가정)으로 구성된다.
int sum = 0;
for (i = 0; i < 10; i++) {
sum += a[i];
}
- 정수 배열에 대한 메모리 접근만 보겠다.
- 첫번 째 배열의 항목 a[0]이 접근된다.
- 가상 주소는 100번이다.
- 하드웨어는 VPN을 계산하여 VPN이 6번인 것을 알아냄
- 하드웨어는 TLB에서 해당 VPN을 검색한다.
- 미스가 발생하면 VPN은 6번에 대한 물리 페이지 번호를 찾아 TLB를 갱신한다.
- a[1]을 접근한다. TLB 히트! (배열의 두번째 항목은 첫번 째 항목과 같은 페이지에 존재하기 떄문)
- 이미 필요한 변환 정보가 이미 TLB에 탑재되어있다.
- a[2]또한 히트
- 같은 원리로 a[3], a[7]은 TLB 미스가 발생하여 TLB를 갱신한다.
- 배열 원소를 읽는 TLB 동작은 70%로 히트가 된다.
- 일반적인 경우 페이지는 4KB이다. 예제와 같이, 정수 배열을 연속적으로 접근하는 프로그램의 경우 TLB의 사용은 큰 성능 개선 효과를 가져올 것이다. 페이지 접근 시 한번에 미스만 발생하기 때문이다.
- 만약 예제 프로그램이 루프 종료 후에도 배열을 사용한다면, 성능은 더욱 개선될 것이다. 모든 주소 변환 정보가 TLB에 탑재되어 있기 때문이다. TLB가 모든 주소 변환 정보를 저장할 정도로 충분히 크다면 모두 히트할 것ㅇ다.
- 이 경우에서는 시간 지역성(한번 참조된 메모리 영역이 짧은 시간 내에 재 참조되는 현상)으로 인해 TLB의 히트율이 높아진다.
- TLB의 성공 여부는 프로그램의 공간 지역성과 시간 지역성 존재 여부에 달려있다.
팁: 가능하면 캐싱을 사용하자
캐싱은 컴퓨터 시스템에서 사용되는 가장 근본적인 성능 개선 기술들 중 하나이다.
하드웨어 캐시 사용의 근본 취지는 명령과 데이터 참조에 있어서 지역성을 활용하자.
시간 지역성(temporal locality)
- 최근에 접근된 명령어 또는 데이터는 곧 다시 접근될 확률이 높다
공간 지역성
- 프로그램이 메모리 주소 x를 읽거나 쓰면 x와 인접한 메모리 주소를 접근할 확률이 높다
TLB 미스는 누가 처리할까?
- TLB 미스를 하드웨어가 처리하게 하도록 설계
- 미스 발생 시 페이지 테이블에서 원하는 페이지 테이블 엔트리를 찾고 변환 정보를 추출하여 TLB를 갱신한 후 명령어를 재실행한다.
- 인텔 x86CPU가 하드웨어로 관리되는 TLB의 대표적인 예이다. (CISC)
- TLB 미스를 소프트웨어가 처리하도록 설계
- TLB에서 주소 찾는 것이 실패하면 하드웨어는 exception 시그널을 발생시킨다.
- 예외 시그널을 받은 웅영체제는 명령어 실행을 중지하고, 실행 모드를 커널로 변경하여, 커널 코드 실행을 준비한다. (특권 level을 상향 조정)
- 트랩 핸들러를 실행하고, 이 핸들러는 페이지 테이블을 검색하여 변환 정보를 찾고, TLB 접근이 가능한 특권 명령어를 사용하여 TLB를 갱신한 후에 리턴한다.
- MIP R10K 나 Sun의 SPARC v9가 대표적인 예 (RISK)
- TLB 미스를 처리하는 트랩 핸들러는 시스템 콜 호출 시 사용되는 트랩 핸들러와 차이가 있다.
- 시스템 콜 호출 시 사용되는 트랩 핸들러는 다음 명령어를 실행한다.
- TLB 미스 처리는 명렁어를 다시 실행시켜야한다.
- 운영체제는 트랩 발생의 원인에 따라 현재 명령어의 PC값 혹은 다음 명령어의 PC값을 저장해야한다.
- TLB를 소프트웨어로 관리하는 방식의 주된 장점은 유연성과 단순함이다.
- 운영체제는 하드웨어 변경없이 페이지 테이블 구조를 자유로이 변경할 수있다.
- 미스가 발생했을 때 하드웨어는 별로 할일이 없다.
TLB의 구성: 무엇이 있나?
- TLB는 32, 64, 또는 128개의 엔트리를 가지며, 완전연관 방식으로 설계된다.
- 변환 정보는 TLB 내에 어디든 위치할 수 있으며, 원하는 변환 정보를 찾는 검색은 TLB 전체에서 병렬적으로 수행한다.
VPN | PFN | 다른비트들
- 변환 정보 저장 위치에 제약이 없도록 각 항목마다 VPN과 PFN이 있다.
- 다른 비트에는 valid bit와 protection bit도 있어서 페이지테이블이랑 똑같이 동작함, 그리고 주소공간 식별자, 더티 비트도 존재
TLB의 문제 : 문맥 교환
TLB를 사용하면서 프로세스간 문맥 교환시 주소 공간들로 인해 새로운 문제가 등장한다. TLB에 있는 가상 주소와 실제 주소 간의 변환 정보는 탑재시킨 프로세스에서만 유효하다. 다른 프로세스들에게는 의미가 다. 새로운 프로세스에서는 이전에 실행하던 프로세스의 변환 정보를 사용하지 않도록 주의해야 한다.
예제
- 프로세스 P1이 실행중이라고 가정하자.
- 이 프로세스는 TLB가 자신에게 유효한 변환 정보를 캐싱하고 있다고 가정한다. (P1의 페이지 테이블의 내용을 TLB가 가지고 있다고 가정하자)
- P1의 10번째 가상 페이지가 물리 프레임 100에 매핑되어있다고 하자.
- 또다른 프로세스 P2가 있고, 운영체제가 곧 문맥 교환을 수행하기로 결정하여 이 프로세스를 실행시키려 한다.
- P2의 10번째 가상 페이지는 물리 프레임 170에 매핑 되어있다고 가정하자.
- 위의 TLB에는 문제가있다. VPN10에 대한 변환 정보가 두개가 존재하는 것이다. 하지만 어떤 프로세스를 위한 항목인지 알 길 이없다.
핵심 질문
- 문맥 교환 시 TLB 내용을 어떻게 관리하는가
- 문맥 교환 시 실행될 프로세스에게는 이전 프로세스가 사용한 TLB 정보는 의미가 없다. 하드웨어 또는 운영체제는 이러한 문제를 해결하기 위해 무엇을 해야하는가?
문맥 교환을 수행할 때 다음 프로세스가 실행되기 전에 기존 TLB를 비운다.
- 페이지 테이블 베이스 레지스터가 변경될 때 TLB를 비운다.
- But 새로운 프로세스가 실행될 때 데이터와 코드 페이지에 대한 접근으로 인한 TLB 미스가 발생한다.
- 문맥 교환이 빈번하게 발생한다면 성능에 큰 부담이다.
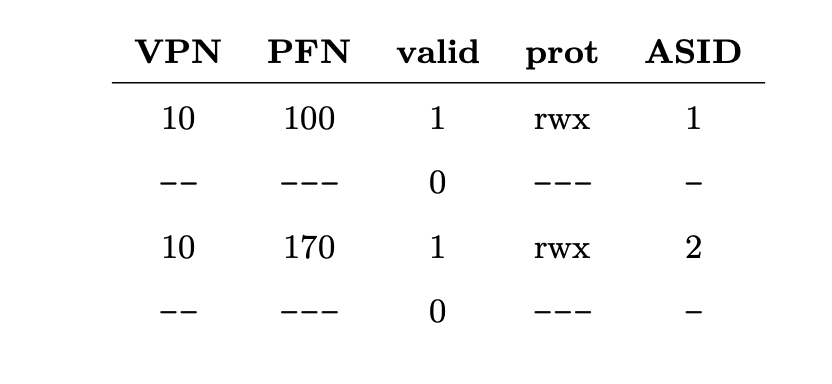
- 이 부담을 개선하기 위해 문맥 교환이 발생하도록 TLB의 내용을 보존할 수 있는 하드웨어 기능을 추가하였다. TLB 내에 주소 공간 식별자(address space identifier, ASID) 필드를 추가하는 것이다.
- PID와 대략적으로 유사하다. 단 ASID는 좀 더 작은 비트로 표현한다.
- 문맥 전환 시 운영체제는 새로운 ASID값을 정해진 레지스터에 탑재한다.
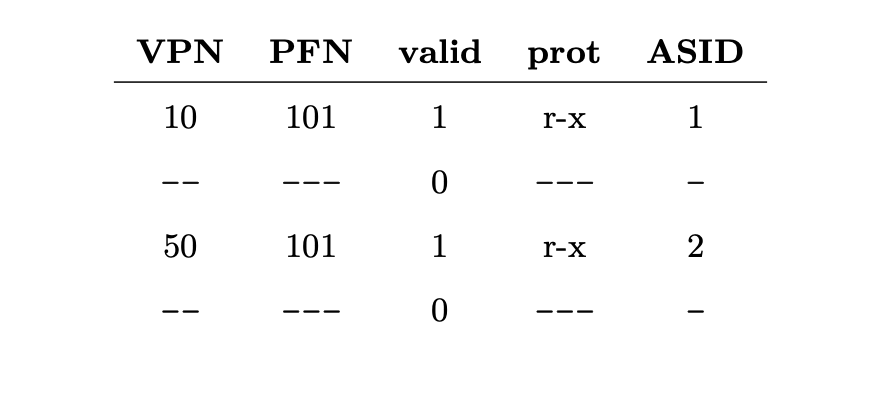
- 이러한 경우도 생길 수 있다. 두개의 프로세스들이 하나의 물리 페이지를 공유하면 프로세스 1이 물리 페이지 101을 프로세스 2와 공유하고 있다. P1은 이 페이지를 자신의 주소 공간의 10번째 페이지에 매핑하고 있으며P2는 자신의 주소 공간의 50번째 페이지에 매핑하고 있다. 코드 페이지를 공유하는 것은 (바이너리에서든 또는 공유 라이브러리이든) 사용되는 물리 페이지의 수를 줄일 수 있기 때문에 유용하다. 그리고 공유 페이지를 사용하면 메모리 부하도 줄일 수 있다.
교체 정책
모든 캐시가 그러하듯이 TLB에서도 캐시 교체 정책이 매우 중요하다. TLB에 새로운 항목을 탑재할 때, 현재 존재하는 항목 중 하나를 교체 대상으로 선정해야한다. 어느 것을 선택해야 할까?
- TLB에 새로운 항목을 추가할 때 어떤 항목을 교체 해야할까? 목표는 히트 비율을 증가 시켜 성능을 개선해야한다.
- 이 내용은 메모리 간의 페이지 스왑 부분에서 상세히 다루도록 하고,
- 한가지 흔한 방법은 최저 사용 빈도(least-recently-used, LRU) 항목을 교체하는 것이다.
- LRU는 메모리 참조 패턴에서 지엯ㅅ겅을 최대한 활용하는 것이 목적이다.
- 사용되지 않은지 오래된 항목일 수록 앞으로 사용될 가능성이 작으며 교체 대상으로 적합하다는 가정에 근거한다.
- 또다른 정책은 랜덤 교체 정책이다. 교체 대상을 무작위로 정한다. 랜덤 교체 정책은 떄떄로 잘못된 결정을 내릴 수 있다. 하지만 간단하고 예외상황의 발생을 피할 수 있다는 장점이 있다.
- LRU같은 합리적인 정책은 TLB가 n+1 페이지들에 대해서 반복문을 수행하는 프로그램에 사용될 경우 최악의 TLB 미스를 생성하게 된다.
실제 TLB
실제 TLB가 어떻게 생겼는지 간략히 살펴보자. MIPS R4000을 예로 들어보자

- 주소 공간: 32-bit 가상 주소 → 4 GB (0x00000000 ~ 0xFFFFFFFF)
- 페이지 크기: 4 KB (2¹² 바이트) → Offset 12 비트
- 가상 페이지 번호(VPN): 32−12 = 20 비트 가 예상인줄 알았지만, 실제 TLB에는 19 비트만 사용
- 왜냐하면 주소 공간 절반(2 GB)만 사용자 공간으로 할당, 나머지는 커널 영역
| VPN | 19 | 가상 페이지 번호 (상위 19 비트, 사용자 공간만) |
| PFN | 24 | 물리 프레임 번호 → 2²⁴×4 KB = 64 GB 물리 메모리 지원 |
| ASID | 8 | Address Space ID → 프로세스 식별 (256개 프로세스 분리) |
| Global (G) | 1 | 전역 페이지 플래그 → 설정 시 ASID 무시, 모든 프로세스에서 공유 가능 |
| Coherence (C) | 3 | 캐시 일관성 상태 표시 |
| Dirty (D) | 1 | 쓰기 발생 여부 표시 → 나중에 메모리에 다시 기록 여부 결정 |
| Valid (V) | 1 | 이 엔트리가 유효한 매핑 정보를 담고 있는지 표시 |
| Page Mask | – | (지원 시) 다양한 페이지 크기 선택용 필드 (여기서는 생략) |
| Unused | 1 | 미사용 비트 |
'Fundamentals > OS' 카테고리의 다른 글
| [병행성 #1] 개요, 쓰레드 vs 프로세스 (0) | 2025.07.04 |
|---|---|
| [메모리 가상화 #6] 페이지 스왑, 페이지 폴트 (1) | 2025.07.02 |
| [메모리 가상화 #4] 페이징 (1) | 2025.06.30 |
| [메모리 가상화 #3] 빈 공간 관리 (1) | 2025.06.28 |
| [메모리 가상화 #2] 세그멘테이션 (0) | 2025.06.28 |
'Fundamentals/OS' 관련글
더보기




Comments