[메모리 가상화 #2] 세그멘테이션 본문
베이스와 바운드 레지스터를 사용하면 운영체제는 프로세스를 물리 메모리의 다른 부분으로 쉽게 재배치할 수 있다.
하지만 이런 단점이있다.
- 메모리 낭비가 심하다.
- 여러 프로세스를 연속 영역에 할당하고 제거하다 보면, 메모리 여기저기에 작은 빈 공간이 흩어짐 (조각남) 이 조각난 빈 공간들은 개별로는 작아서 새 프로세스를 못 담는다.
- 전체 사용 가능 메모리는 충분해도, 연속 공간이 부족해서 새 프로세스를 못 올림.
- 유언성이 떨어진다.
- 실행 중 프로세스의 크기가 커지면 이미 연속 공간으로 고정된 베이스-바운드 방식에서는 그 뒤 영역이 다른 프로세스가 쓰고 있으면 확장 불가.
- 실행 중에 다른 프로세스로 인해 공간을 옮겨야 한다면?
- 베이스 값을 바꿔야 하고, 이 과정에서 프로그램의 모든 주소 참조를 안전히 관리해야 함.
- 단일 연속 블록만을 허용하기 때문에 이동 비용이 크고 운영체제가 부담이 큼.
세그멘테이션 : 베이스/바운드의 일반화
이 문제를 해결하기 위한 아이디어가 세그멘테이션 이다.
세그멘트 기반 주소 공간이란 ?
- 세그멘트(segmentation) 는 프로그램을 의미적 단위(코드, 데이터, 힙, 스택 등)로 나눠서 관리하는 방식이다.
- 각 세그멘트는 별도의 Base (시작 물리주소) 와 Bound (크기) 를 가지고, 이를 MMU가 관리한다.
- 세그멘테이션을 사용하면 운영체제는 각 세그멘트를 물리 메모리의 각기 다른 위치에 배치할 수있고,
- 사용되지 않는 가상 주소 공간이 물리 메모리를 차지하는 것을 방지할 수 있다.
즉, 하나의 프로그램은 논리적으로 여러 개의 세그멘트를 가지며, 각 세그멘트마다 독립적으로 물리 메모리에 배치됨
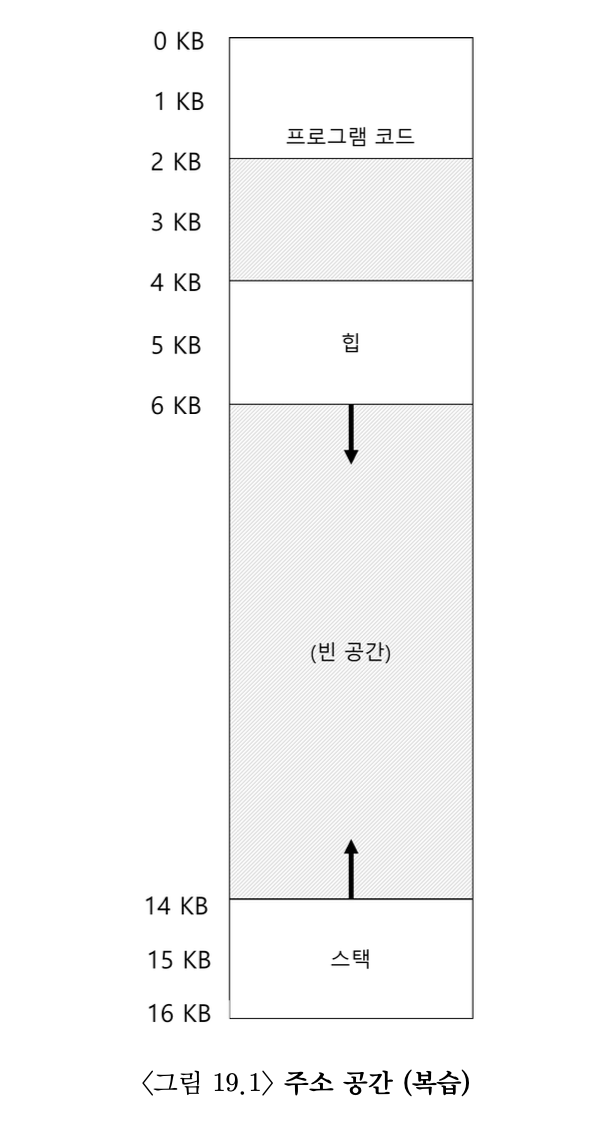

예제: 코드 세그멘트
- 가상주소 100 번지를 참조한다고 가정
- 코드 세그멘트:
- Base = 32 KB
- Bound = 2 KB
→ 이 주소는 코드 세그멘트에 속함 (가상주소 0~2047) (그림 19.1)
→ 오프셋 = 100 (세그멘트의 가상 시작주소는 0)
→ 물리주소 = Base(32 KB) + 오프셋(100)
= 32768 + 100
= 32868.
→ 오프셋 100은 Bound(2 KB = 2048) 이내 → OK!
예제: 힙 세그멘트
- 가상주소 4200 참조한다고 가정
- 힙 세그멘트:
- Base = 34 KB
- Bound = 2 KB
- 가상주소: 4 KB ~ 6 KB (즉, 4096 ~ 6143)
→ 힙 세그멘트의 가상 시작주소는 4096
→ 오프셋 = 4200 - 4096 = 104
→ 물리주소 = Base(34 KB) + 오프셋(104)
= 34816 + 104
= 34920.
→ 오프셋 104는 Bound 2 KB 이내 → OK!
예제: 잘못된 주소 접근
만약 힙 세그멘트가 2 KB 인데,
가상주소 7 KB(= 7168)를 참조하면?
힙의 가상 시작주소: 4096
따라서 오프셋 = 7168 - 4096 = 3072
하지만 Bound는 2 KB = 2048 따라서 3072 > 2048 범위 초과가 일어남.
MMU가 즉시 감지한 후 트랩(segment fault) 발생 OS가 프로세스를 종료하거나 예외 처리!
이런 경우를 세그멘트위반(segment violation) 또는 세그멘트 폴트(segment fault). 라 부름
스택
스택은 다른 세그먼트들과 반대 방향(높은 주소 → 낮은 주소)으로 확장되기 때문에, 변환 방식과 하드웨어 처리 방식이 조금 다르다
- 스택 세그먼트의 가상 주소 구간: 16 KB ~ 14 KB (→ 감소 방향)
- 물리 주소 구간: 28 KB ~ 26 KB (→ 감소 방향)
- 세그먼트 크기: 2 KB
- Base (확장 시작점): 28 KB
- 가상 주소 접근: 15 KB (0x3C00)
공유 지원
>
- 메모리를 절약하기 위해 때로는 주소 공간들 간에 특정 메모리 세그멘트를 공유하는 것이 유용하다
- 특히 코드 공유가 일반적
- 공유 지원을 위해 하드웨어에 protection bit의 추가가 필요
- 세그멘트를 읽거나 쓸 수 있는지
- 세그멘트의 코드를 실행시킬 수 있는지
- 코드 세그멘트를 읽기 전용으로 설정하면 주소 공간의 독립성을 유지하면서도, 여러 프로세스가 주소 공간의 일부를 공유할 수 있다.
- 각 프로세스는 여전히 자신의 전용 메모리를 사용하고 있다고 생각하지만 운영체제는 이 변경이 불가능하도록 설정된 메모리 영역을 비밀리에 공유시켜 그러한 환상을 유지토록 한다.

- 공유 지원을 위해 앞서 언급한 하드웨어 알고리즘이 수정되어야한다.
- 가상 주소가 범위에 있는지 확인하는 것 이외에 특정 액세스가 허용되는지를 확인해야 한다.
소단위 대 대단위 세그멘테이션
- 소수의 세그멘트(코드, 스택, 힙) 만을 지원하는 시스템에만 초점을 맞췄었는데, 이를 대단위 라고 생각할 수 있다.
- 일부 초기 시스템은 주소 공간을 작은 크기의 공간으로 잘게 나누는 것이 허용되었기 때문에, 소단위 세그멘테이션이라고 부른다.
- 많은 수의 세그멘트를 지원하기 위해서는 여러 세그멘트의 정보를 메모리에 저장할 수 있는 세그멘트 테이블 같은 하드웨어가 필요하다. 세그멘트 테이블을 이용하면 매우 많은 세그멘트를 손쉽게 생성하고 융통성 있게 세그멘트를 사용할 수 있다.
외부 단편화 문제

- 이전에 각 주소 공간의 크기가 동일하다고 가정했는데, 지금은 프로세스가 많은 세그멘트를 가질 수 있고, 크기가 다를 수 있다.
- 위 예(왼쪽그림)에서 새로운 프로세스가 생성되어 20KB 을 할당하려고 한다 가정하자.
- 위 예제에서는 24KB의 빈 공간이 존재하지만, 연속된 공간이 아니라 세게의 청크로 나누어져 있다.
- 운영체제는 20KB의 요청을 충족시킬 수 없다.
- 이 문제의 해결책 중 한 가지는 기존의 세그멘트를 정리하여 물리 메모리를 압축하는 것이다.
- 예를들어 운영체제는 현재 실행 중인 프로세스를 중단하고, 그들의 데이터를 하나의 연속된 공간에 복사하고, 세그멘트 레지스터가 새로운 물리메모리 위치를 가리키게 하여 자신이 작업할 큰 공간을 확보 할 수 있다.
- 하지만 세그멘트 복사는 메모리에 부하가 큰 연산이고, 상당량의 프로세서 시간을 사용하기 때문에 압축은 비용이 많이 든다.
- 간단한 방법은 빈 공간 리스트를 관리하는 알고리즘을 사용하는 것이다.
- 빈 공간 알고리즘은 할당 가능한 메모리 영역들을 리스트 형태로 유지한다.
- 최적 적합(best fit)
- 먼저 빈 공간 리스트를 검색하여 요청한 크기와 같거나 더 큰 빈 메모리 청크를 찾는다. 그 후, 후보자 그룹 중에서 가장 작은 크기의 청크를 반환한다.
- 빈 블럭을 찾기 위해 항상 전체를 검색해야 하기 때문에 성능 이슈
- 최악 적합(worst-fit)
- 가장 큰 빈 청크를 찾아 요청된 크기 만큼만 반환하고 남는 부분은 빈 공간 리스트에 계속 유지한다.
- 항상 빈 공간 전체를 탐색해야 하기 때문에 이 방법 역시 높은 비용을 지불해야 한다
- 단편화가 여전히 큼
- 최초 적합(first-fit)
- 요청보다 큰 첫 번째 블럭을 찾아서 요청만큼 반환한다. 먼저와 같이 남은 빈 공간은 후속 요청을 위해 계속 유지된다.
- 속도가 빠르다는 것이 장점이다.
- 다음 적합(Next Fit)
- 마지막으로 찾았던 원소를 가리키는 추가의 포인터를 유지한다. 아이디어는 빈 공간 탐색을 리스트 전체에 더 균등하게 분산시키는 것이다.
- 최적 적합(best fit)
- 알고리즘이 아무리 정교하게 동작한다 해도 외부 단편화는 여전히 존재한다.
출처 : 운영체제 아주 쉬운 세가지 이야기
'Fundamentals > OS' 카테고리의 다른 글
| [메모리 가상화 #4] 페이징 (1) | 2025.06.30 |
|---|---|
| [메모리 가상화 #3] 빈 공간 관리 (1) | 2025.06.28 |
| [메모리 가상화 #1] 멀티프로그래밍, 주소공간, 주소공간 변환 (2) | 2025.06.20 |
| [CPU 스케줄링 #3] 멀티 프로세서 SQMS, MQMS (1) | 2025.06.17 |
| [CPU 스케줄링 #2] 비례배분, 추첨 스케줄링, 보폭 스케줄링 (2) | 2025.06.16 |



